1:N 패턴에서의 MongoDB 모델링
1. 주제
Node.js로 개발할 때 가장 쉽게 접근할 수 있는 데이터베이스로는 MongoDB가 있습니다. MongoDB는 No-SQL 데이터베이스로 그 형식은 JSON과 매우 유사합니다. 이번 일지에서는 사용자 인증 처리 로직이 있는 게시판을 구현하는 경우의 Mongoose 모델 설계 관점에 대해서 다뤄보려고 합니다.
2. MongoDB의 핵심 기능
앞에서 언급한 주제의 내용을 다루기 전에 간단하게 MongoDB의 핵심 기능에 대해서 다루고 넘어가겠습니다. MongoDB는 No-SQL 데이터베이스에 속하며, Excel 파일의 테이블 형식이 아닌 JSON 파일과 유사한 document가 collection으로 그룹화되어 있는 구조입니다.
MySQL과 같은 관계형 데이터베이스의 경우 하나의 파일에 구조화된 데이터가 저장되는 방식이나, MongoDB는 비교적 형태가 자유롭습니다. 예를 들어, MySQL의 경우 특정 테이블의 존재하지 않는 field에 데이터를 입력하는 경우 오류가 발생하나, MongoDB는 해당 데이터를 문서에 추가하여 유연하게 동작합니다.
이를 다른 말로 나타내면 스키마가 없는 상태(schema-less) 라고 합니다. 스키마가 존재하는 MySQL의 경우, 소프트웨어를 설계할 때에는 데이터의 구조에 따라 데이터베이스 구조를 설계하는 방식이라면, MongoDB의 경우에는 스키마가 존재하지 않기 때문에 애플리케이션이 데이터의 구조를 정하는 방식입니다.
따라서, 데이터 구조의 변경이 빈번하게 발생하는 개발 초기 단계에서는 스키마를 재설계할 필요가 없으므로 개발 시간을 단축시킬 수 있습니다. 또한, MySQL의 경우 특정 field에 명시한 데이터 타입을 변경하는 경우 그 과정이 비교적 복잡한 반면에, MongoDB는 스키마가 없는 데이터 모델을 통해 가변적인 속성을 갖는 데이터를 표현할 수 있다는 특징이 있습니다.
3. Linked Document
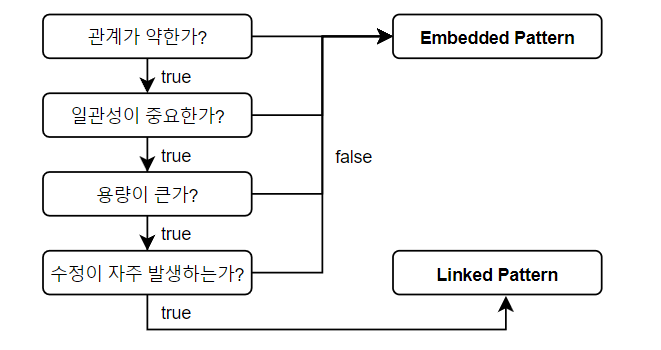
스키마를 설계할 때에는 데이터 간의 관계를 먼저 따져야 합니다. 예를 들어, 게시글과 댓글의 관계를 생각해봅시다. 하나의 고유한 게시글에는 여러 개의 댓글이 존재할 수 있는 반면, 하나의 고유한 댓글은 여러 개의 게시글에 포함될 수 없으며, 이와 같은 패턴을 1:N이라고 합니다. MySQL을 사용하면 이와 같은 패턴을 다음과 같은 형태로 나타낼 수 있습니다.
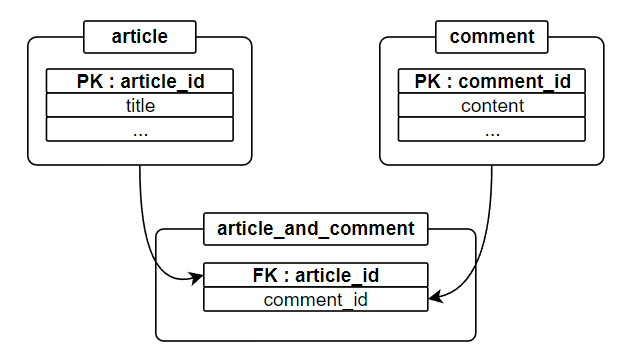
MongoDB에서도 이와 같은 형태로 나타낼 수 있는데, 이를 Linked document라고 합니다. Linked 방식은 관계형 데이터베이스와 같이 서로 다른 두 개의 테이블로 분리시켜 관계를 결정짓는 방식입니다. 따라서, 자식 객체가 부모 객체와는 별개로 단독으로 사용될 때 적용할 수 있으며, 부모와 자식 객체 간 독립적인 document로 구성되어 있으므로 용량을 상대적으로 줄일 수 있습니다. 반면, 부모와 자식 객체를 모두 조회할 때에는 부모 객체가 존재하는 collection과 자식 객체가 존재하는 collection을 모두 조회하여야 하므로 상대적으로 읽기 성능이 저하된다는 단점이 있습니다.
- 예) 게시글과 댓글의 관계
- 게시글에 해당하는 댓글 정보를 조회하는 경우 여러번의 읽기 과정 필요(읽기 성능 저하)
- 데이터의 일관성이 상대적으로 중요할 때 적용
4. Embedded Document
또 다른 방법으로는 부모 객체에 자식 객체를 포함시키는 방식이 있으며, 이를 Embedded document 라고 합니다. Embedded 방식은 자식 객체가 부모객체 내에서만 사용될 때 사용하며, 예를 들어, 게시글에 카테고리를 나타내고자 할 때 고려할 수 있습니다.
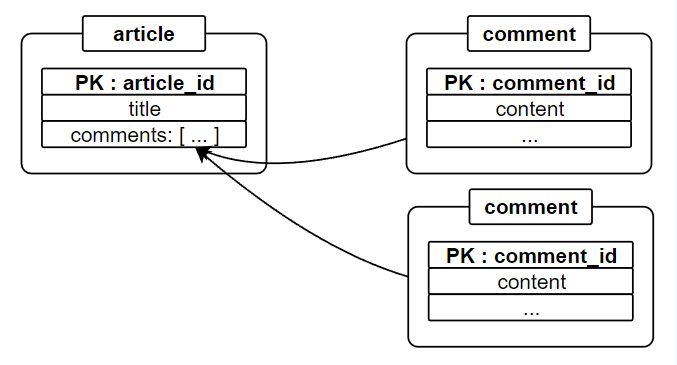
- 예) 게시글과 카테고리 항목의 관계
- 한 번의 읽기로 모든 정보 조회(읽기 성능 향상)
5. Linked와 Embedded 방식 비교
Linked와 Embedded 방식은 상황에 따라 장점과 단점이 확연히 구분되므로 데이터의 관계에 따라 적절한 방식을 선택하여야 합니다. 예를 들어, 게시글과 댓글의 스키마를 Embedded document로 나타내면 다음과 같습니다.
/* Embedded Pattern */
{
"_id": 1,
"title": "first article",
"content": "first article's content",
"user": {
"_id": ObjectId("506ebba74c935cb364575e95"),
"name": "최원영"
},
"comments": [
{
"_id": 1,
"content": "fisrt comment",
"user": {
"_id": ObjectId("ebb364575e95a74c935506cb"),
"name": "홍길동"
},
},
{
"_id": 2,
"content": "second comment",
"user": {
"_id": ObjectId("35506cb34c95e956457ebba7"),
"name": "아이유"
}
}
]
}
앞서 언급하였듯이 Embedded document는 읽기가 한 번 수행될 때 필요한 모든 데이터를 조회할 수 있어야 하므로 자식 객체에서 필요한 모든 데이터를 부모 객체에 모두 포함하고 있습니다. 이와 같이 설계한 경우 몇 가지 문제점이 발생할 수 있는데, 이는 다음과 같습니다.
- 자식 객체의 속성을 변경한 경우, 부모 객체에 포함된 자식 객체의 속성은 변경되지 않는다.
- 자식 객체로부터 필요한 모든 속성을 부모 객체에 포함하고 있으므로 document의 용량이 증가한다.
- 새로운 자식 객체를 추가하는 경우 부모 객체의 속성을 수정하여야 하므로 비효율적이다.
- 하나의 document는
16MB의 용량 제한이 있으며, 용량 제한으로 인해 부모 객체에 자식 객체를 추가할 수 없는 상황이 발생할 수 있다.
이와 같이 새로운 document 생성 및 기존 document의 수정이 빈번하게 발생하는 경우 Embedded 방식은 적절하지 않습니다. 이번에는 위의 상황을 Linked 방식으로 나타내면 다음과 같습니다.
/* Linked Pattern */
/* articles */
{
"_id": 1,
"title": "first article's title",
"content": "first article's content",
"userId": ObjectId("506ebba74c935cb364575e95")
}
/* comments */
{
"_id": 1,
"content": "first comment",
"articleId": 1,
"userId": ObjectId("ebb364575e95a74c935506cb")
},
{
"_id": 2,
"content": "second comment",
"articleId": 1,
"userId": ObjectId("35506cb34c95e956457ebba7")
}
Linked 방식을 적용하면 자식 객체의 식별값을 참조할 수 있으며, 참조하는 collecion이 여러 개인 경우 MongoDB 내부의 표준 참조 기법인 DBRef를 사용할 수 있습니다. 이는 참조하는 collection과 key, value를 함께 명시하는 참조 방법으로 하나의 document가 여러 개의 collection에 존재하는 document를 참조할 수 있도록 해줍니다.
6. 최종 정리
이번 글에서는 1:N 관계 패턴의 MongoDB 모델링 방식에 대해서 정리해 보았습니다. 위에서 언급한 내용 외에도 여러 개의 고려사항이 있는데, 이를 간단히 정리하면 다음과 같습니다.
-
Embedded
- 하나의 document에는 최대
16MB용량의 데이터를 저장할 수 있으므로 모델링 시 용량을 고려하여야 한다. - 데이터 생성, 수정이 빈번하게 발생하는 경우 Embedded 방식보다는 Linked 방식을 권장한다.
- 한 번의 쿼리로 필요한 모든 데이터를 조회할 수 있으므로 읽기 성능 향상을 기대할 수 있다.
- 하나의 document에는 최대
-
Linked
- 여러 개의 collection을 참조하므로 복잡하게 느낄 수 있으나, 유연한 데이터 구조를 갖고 있다.
- 대체적으로 다른 collection의
_id를 참조하므로 용량 제한을 걱정하지 않아도 된다. - Embedded 방식에 비해 상대적으로 강한 일관성을 나타낸다.
따라서, 사용자 인증 처리 로직이 있는 게시판을 구현하고자 할 때에는 Linked 방식으로 모델링하는 것이 효율적이라고 할 수 있습니다. 다른 관계 패턴의 모델링에서 데이터 조회 시 읽기 속도가 매우 중요한 경우라고 한다면 Embedded 방식을 적용할 수 있는데, 이와 같이 고려할 상황에 따라 설계 방식에 차이가 발생할 수 있습니다.